Adaptive MaxDiff
This article presents the example QEX file for the Adaptive MaxDiff methodology (A-MaxDiff). The difference between this method and a "standard" MaxDiff are explained. Instructions on using and updating the example file for your own list of items are also provided.
Background and other articles
There are a few articles already in our Help Centre regarding MaxDiff & use of the Interactive Library. It will be useful to have reviewed these already.
- AskiaDesign: Example of MaxDiff methodology
- AskiaAnalyse: MaxDiff Data analysis
- AskiaDesign: MaxDiff Interactive Library
- AskiaDesign: Interactive libraries in Design 5.4
- AskiaDesign: MaxDiff Table ADC.
Concepts
Research has shown that MaxDiff scores demonstrate greater discrimination among items and between respondents on the items. Since respondents make choices rather than expressing strength of preference using some numeric scale, there is no opportunity for scale use bias.
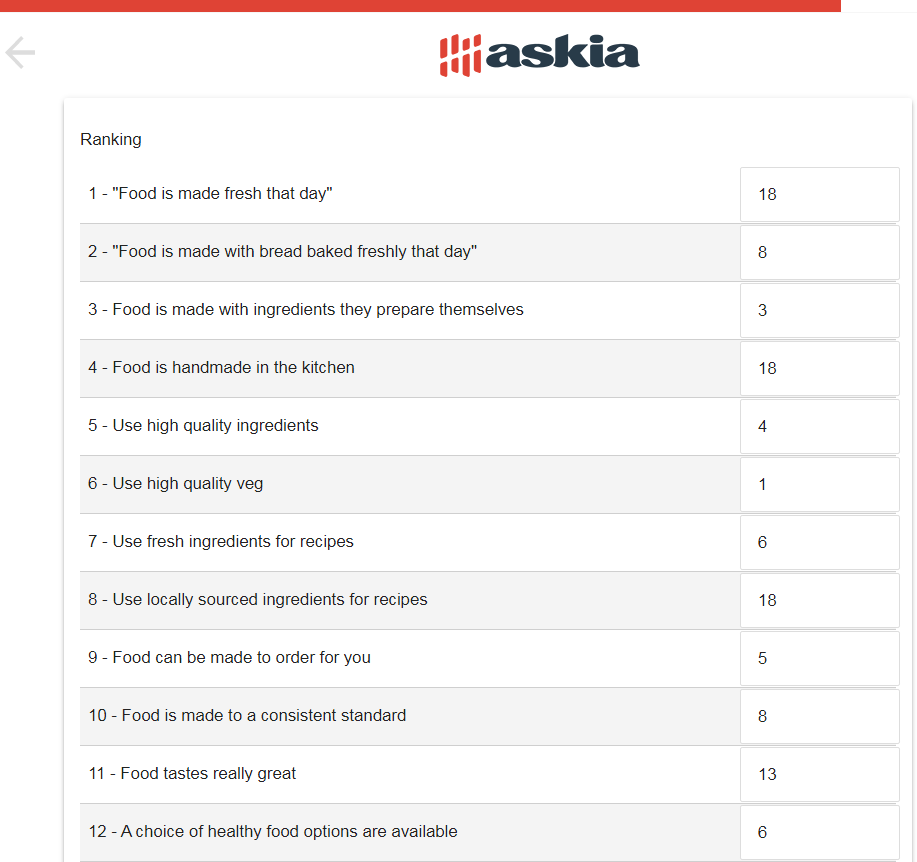
MaxDiff is also known as "best-worst scaling". When conducting a MaxDiff section in an interview, you would expect to see something like the response table below.
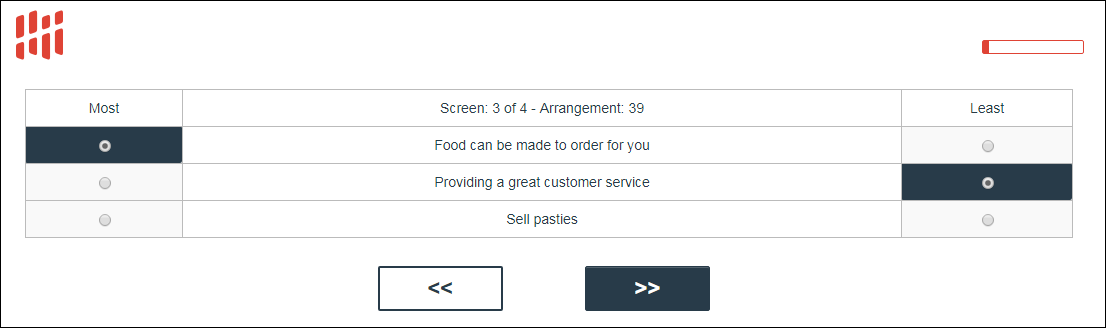
There is a list of items and you are asked their importance over a number of screens. Each screen has a subset of these items (usually 3, 4 or 5) and you are asked to pick your most and least important for each screen.
The arrangement of the screens (the "design") is calculated (can be done by software such as R) such that after all the screens are asked, the answers give a robust indication of how the items are scaled from best to worst.
The key point with standard MaxDiff is that the arrangement of the screens are pre-set and do not adapt to the responses given during the interview. In addition, the number of selectable options on each screen is constant.
However, in Adaptive MaxDiff, the number of selectable options will change. Each round of screens, the items selected as 'Least' are removed from the next round of screens. The number of items on screens therefore diminishes until you get to the start of the last round where you are asked to pick between all those you chose as 'Most'.
So the key point is the routing in the example file takes account of the 'Least' items and removes them from consideration in later rounds, 'adapting' to given responses. Below is a simple diagram to show this more clearly:
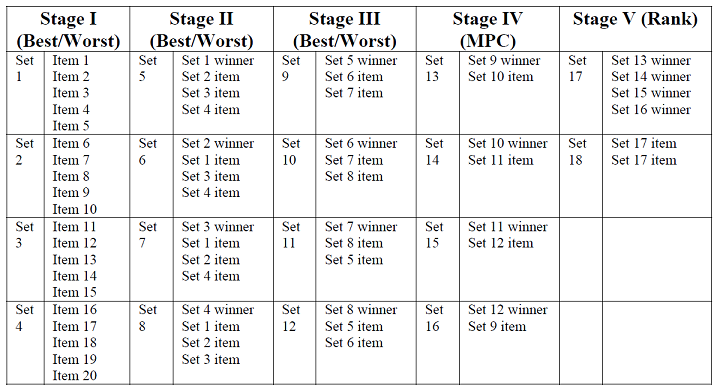
In this example we have 20 items and we start with showing 5 per screen in the first round. Then we discard the four selected least in each round, until the last round where we rank the last 4 winners.
The advantages of adaptive MaxDiff are that greater discrimination between items of importance is achieved. The disadvantages? Well, it could be argued that, since your initial answers create the upcoming arrangements, you do not have as much opportunity to change your mind about items you have rated least important in previous rounds.
This article explores Adaptive MaxDiff in greater depth.
The example
The example QEX has the structure as shown to the left of the screenshot below. Clever programming has been put together by one of the support team, making use of the relatively new routing action: Run an Askia Script.
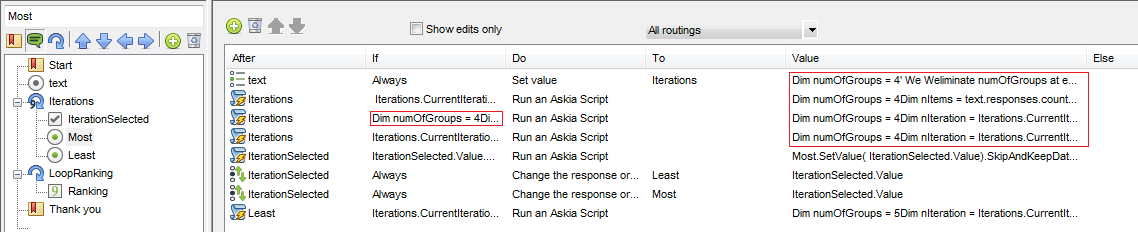
Your list of items goes into the variable text and is linked to by several following questions. The number of items defined in Iterations should run 1 to 20. The first example has 20 items split over 4 groups and can be downloaded here. The routing conditions highlighted above must start with numOfGroups = 4.
If you have less than 20 items e.g. 18, then some of the arrangements in the rounds of screens will have less than the expected number of items to account for this.
In order to increase the number of items, we need to set the additional items and numbers into text and Iterations respectively. As well as this, we need to update the routing conditions above to start with numOfGroups = 5.
This will naturally work with 25 items. The example file can be downloaded here and an example of the data input is shown below.

There are five iterations per round and in the last two iterations, the ranking of the last five winners is decided.
If we try this 22 items, we see there are fewer iterations required to work out winners.

Once all the screens are completed, we have some additional routing for the variables at the end (LoopRanking and Ranking). And as you can probably guess, this ranks all the items in the order of most importance to least. Neat!