🎓 Weighting Algorithm
Definition
The process of weighting consists of changing the weight of the interviews to correct sampling errors or to project a sample up to a known population or universe.
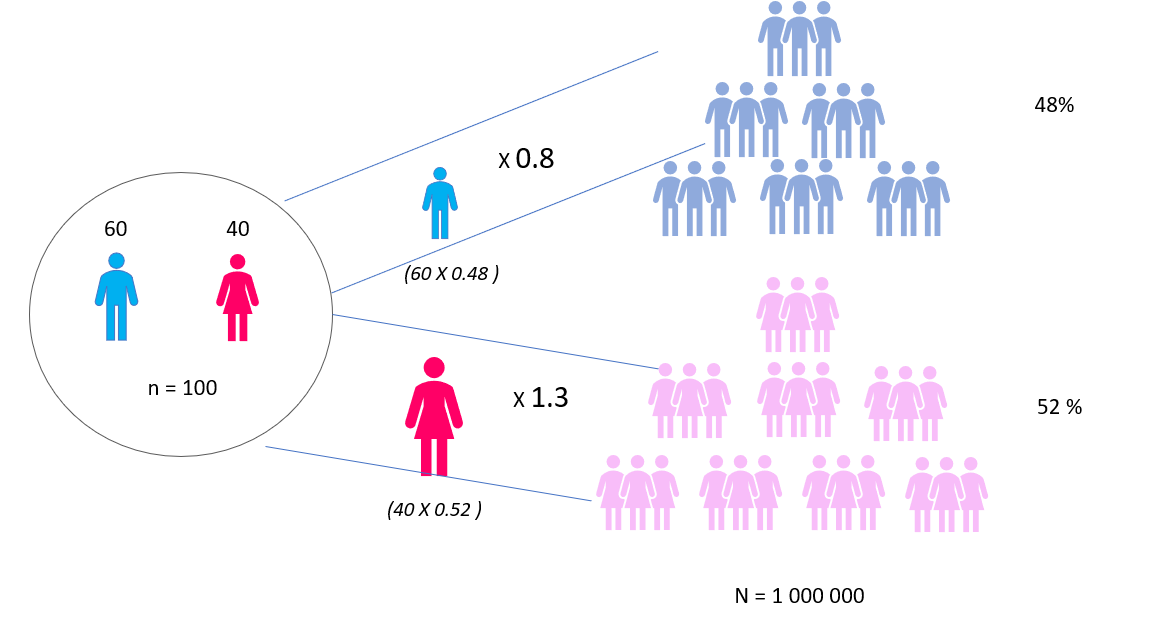
To illustrate this first scenario, we interviewed 60 men and 40 women in our sample. But in the population we have 48 men and 52 women.
To correct this, each time we will do counts on a question, instead of adding 1 for each man, we will add 48/60 = 0.8, and for each woman we will add 52/40= 1.3.
In other words, the under represented categories will have a stronger vote than the over represented ones.
Multiple targets
The process gets more complicated when more than one variable is involved. Let us imagine we want to apply a weighting on gender and social grade (A,B,C). If we have the information on how the gender is defined for each social grade (and hence creating a new variable with 6 cells), we can fall back on the one variable weighting. But if we increase the number of questions and responses in the weighting, the target population frequency in each of the sub-cell may not be known.
Another alternative would be to assume that gender and social grade are independent and therefore, we should observe on each social grades a 50-50 split on gender. But this hypothesis is very restrictive and would very likely skew the results.
Therefore the algorithm is an iterative process.
- First the weights are set to 1 for all interviews.
- The system finds which variable is the furthest from the targets.
- The current weights are changed so this variable fits exactly the targets
- If all variables fit the targets, the process stops otherwise, it starts again at b)
After a few iterations, the weights should converge to an acceptable solution.
The interface 🎬
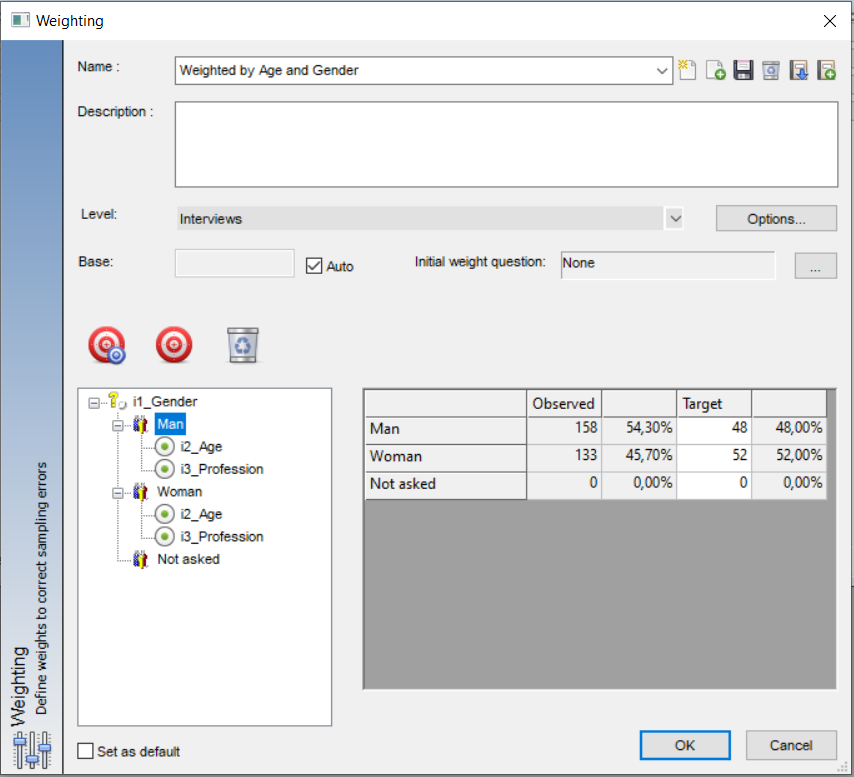
The interface allows to define interlocked weightings at any level of depth where target variables could be different (in frequencies obviously but the questions themselves could be different). And you can have sub-population targets and over all targets (in the example below the question Gender is a target for Less than 24, students and also defined at global level).
Finally, you can specify the base so the results would be extrapolated to the national population.
Algorithm
As explained before, every interview’s weight is initially set to 1. Alternatively, you can specify the initial weight question if you want multi-step weightings (a calculated question can be created from the result of a weighting and used as the initial weight question).
The question the furthest apart from the target is chosen thanks to a Khi² distance calculation (the sample affected could be the whole population or a sub-population).
The weights are then recalculated for the affected sub-population.
The optional maxima for individual interviews are then applied: we can specify that no interview should count more than 5 times a normal weight and no less than 0.1 for instance.
We then check if any observed percentage is different to the theoretical target – or more accurately different by more than a specified threshold: 0,1%, 0.01% or less..
If we are not within the targets, we start again unless we have done already more iterations than authorised by a specified parameter.
Understanding why the algorithms sometimes fails
If a solution cannot be found, the system indicates it to the user and returns the current weights. The details of each iteration are stored in a text report along with the final observed counts next to their targets.
If the sample is large enough and the targets are not too far from the observed population, a solution should be found rapidly.
There are two main reasons for the weighting not to converge:
- Not enough data for one sample
I am stating the obvious here but if you need 10% of your sample to be below 18, and you do not have interviewed any, your sample will not converge.
Similarly, if you only have interviewed 5 out of a 1000 and you still want to achieve 10%, each of these interviews will have a weight of ( 10 / 100) / ( 5 / 1000) = 20.
And if you had specified that an interview cannot count more than 5 times a normal weight, you will not achieve an acceptable solution.
In that case, you will see that the question causing the conflict will be picked again and again.
- Conflicting targets between two questions
This usually happens when there is a strong links between two questions and that the target do not reflect this.
Let us imagine your targets are 11% of students and 10% being less than 24 years old. Now, let is imagine that in your sample all of your students are less than 24 years old. This would mean that you would get at least 11% for the 24 years old cell.
In this case, the algorithm would indefinitely pick the occupation, then the age, then the occupation, etc until it reached the maximum number of iterations.
To know more about error message you get, see 💡 how to modify weighting settings