Penalty Analysis & "Just About Right" (JAR) scales
| Summary | This article provides steps on how to set up a penalty analysis & 'just-about-right' scales in AskiaAnalyse |
| Applies to | AskiaAnalyse |
| Written for | Data Processors, Statisticians, Researchers |
| Keywords | Penalty analysis; Penalty test; JAR; Just-about-right; Mean; Grand mean; More important; Less important; Attributes; Scales; Consumer research; Product; Liking; Affinity; Score |
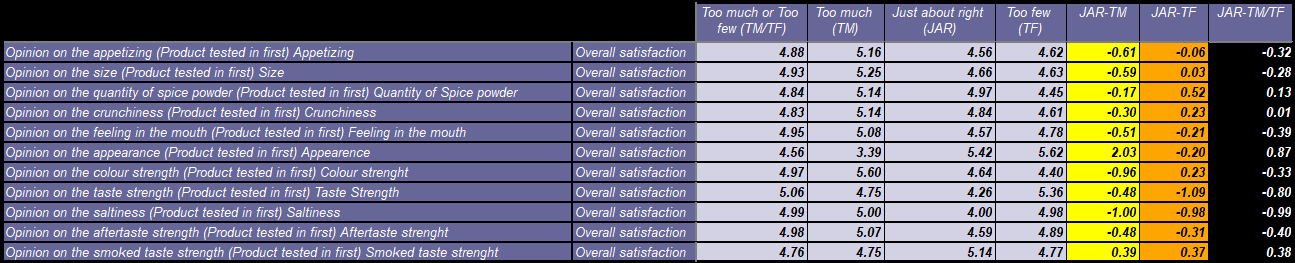
"Just-about-right" penalty analysis measures the change in product affinity or satisfaction (or any other measure) due to that product having "too much" or "too little" of a chosen attribute.
Related articles for useful background:
The example QES file and portfolio can be downloaded here.
In the sort of survey we would use this analysis on, there is an overall satisfaction question about the product. Then this is followed by rating questions on several attributes:
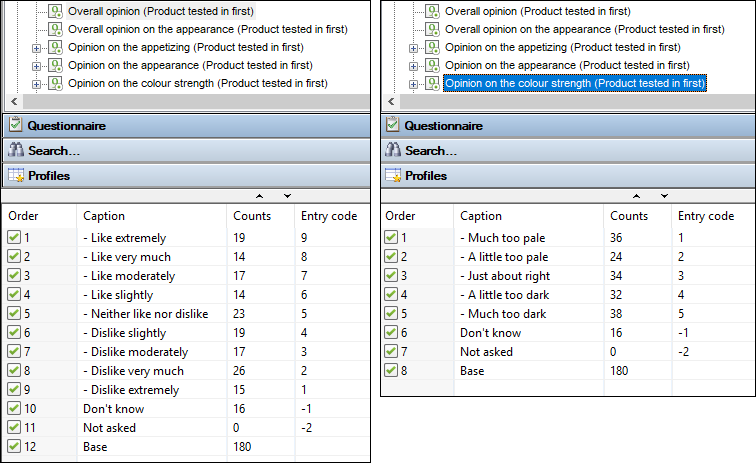
The attribute rating questions should have a middle code: 'Just about right'.
From these we set up grouped variables which reduce the categories to three in number: Too much, JAR, Too little.
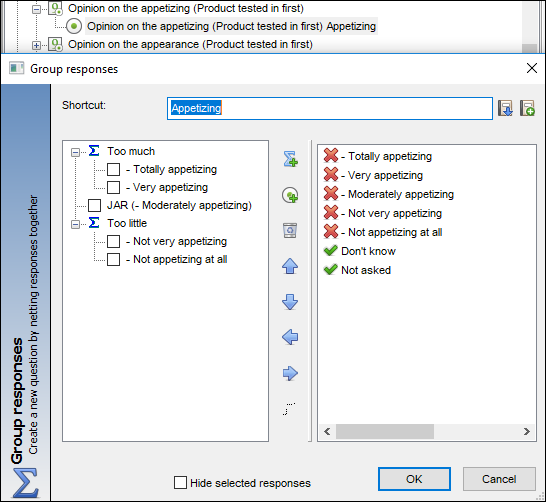
Then we set-up our table definition:
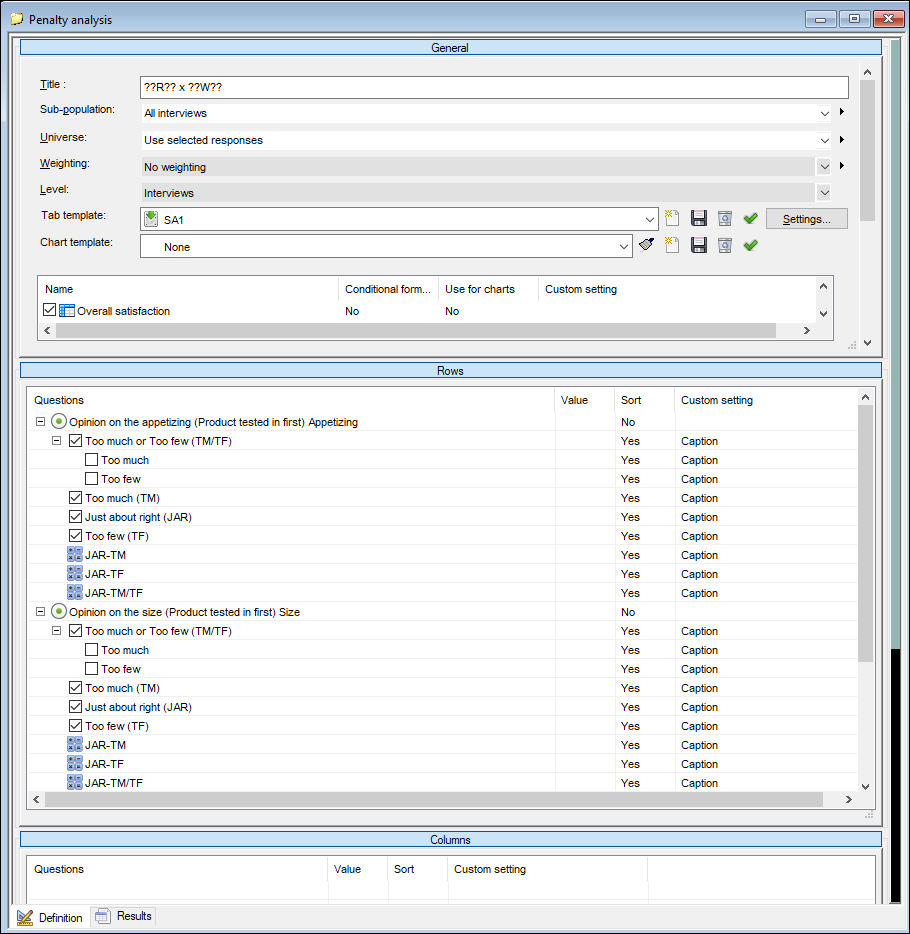
There are three calculated responses per variable in the rows. The scripts for these are simply: 0.
We're just adding these calculated responses to create columns in our table which will have data filled in by the cleaning script used later.
There is one calculation we need in this table, the mean from the overall satisfaction question. The overall satisfaction mean score will be split by the four non-calculated responses in each variable; splits which we need to calculate the final penalty scores.
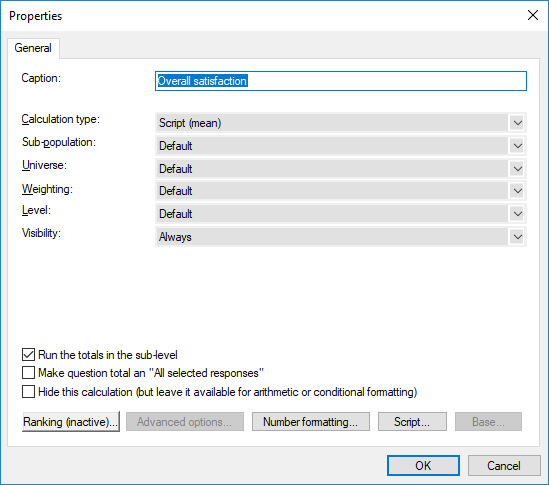
Giving a score from Like extremely (9) to Dislike extremely (1) with the Don't know category marked as 'nr' in order to remove them from the mean score calculation.
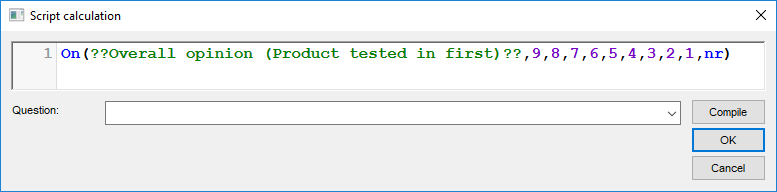
The clean up script required to compute the penalty values:
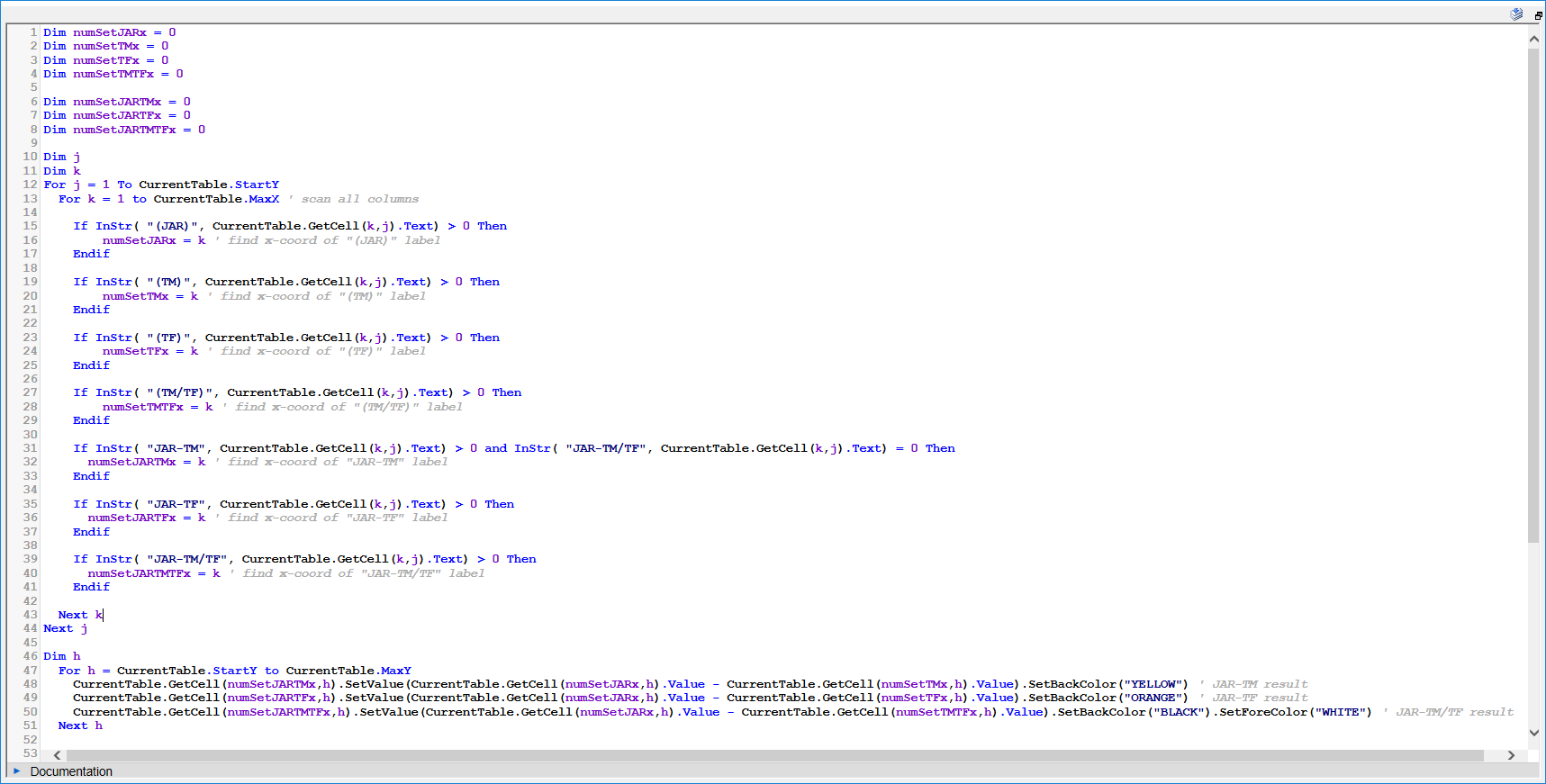
The correct columns to use in the right parts of the final calculation are worked out using text matches between lines of code 10-44. This means you can move columns around and it won't affect the final figures.
So please bear this in mind if your column headers will take different names to those shown; this will mean an update of the texts to match against in the script is required.
Lines of code 46-51 are where the scores are calculated.
The result: